
2026-05-01
Teaching a 1.5B LLM to be a SOC Analyst (Without Burning Down the Network)
Something changed recently. I've been watching attacks on major internet infrastructure that used to require serious expertise - and the people behind some of them are amateurs. They're not writing exploits. They're prompting. Projects like Mythos have found 0-days in established codebases with millions of lines of code by treating vulnerability research as a reasoning task. Software I thought was locked down for years has been cracked open.
The asymmetry is uncomfortable: a capable AI assistant is available to attackers on day one. Defenders are still catching up. The logical response is to deploy an AI on your side - but training one on a live production network is obviously not an option. You need a realistic simulation. And most existing ones don't come close.
The Problem With Existing Cyber Environments
Most cyber-defense environments treat the problem as a classification task: _is this payload malicious?_ The world doesn't work that way. Real attackers don't strike all at once. They establish a foothold, sit quietly for days, pivot laterally, exfiltrate slowly. The threat is a process, not a moment.
I wanted an environment that reflected this - one where:
- Attacks unfold over many steps with stochastic timing
- Early signals are deliberately weak and noisy
- Containment has a real business cost (taking a server offline costs something)
- An adaptive adversary adjusts its pace based on defender behavior
So I built Cybersec OpenEnv: a long-horizon, partially observable Markov decision process (POMDP) where a scripted attacker and an LLM defender play out realistic enterprise attack chains, grounded in MITRE ATT&CK techniques.
Why a 1.5B Parameter Model?
The defender is Qwen2.5-1.5B-Instruct, fine-tuned with GRPO (Group Relative Policy Optimization) via Hugging Face TRL and Unsloth 4-bit QLoRA on a single Colab T4 GPU. The size is deliberate.
Iteration speed. Multiple full RL training cycles need to fit on consumer hardware. A 70B model makes that impossible.
Privacy. Enterprise security telemetry - network topology, identity graphs, forensic signals - should never leave your infrastructure. Local, air-gapped models are the only defensible architecture for this use case.
Deployment. If I want autonomous SOC agents running everywhere, they have to fit on standard enterprise hardware. The proof of concept has to work at the size that scales.
The Environment
Three training scenarios and one held-out evaluation scenario, all modeled on real attack kill-chains:
| Scenario | Attack Chain | Horizon |
| ---------------------------------- | ------------------------------------------------------------------------ | :------: |
| supply_chain_token_drift | CI-token theft → poisoned artifact → payments pivot → warehouse exfil | 70 ticks |
| federated_identity_takeover | Spearphish → MFA fatigue → helpdesk pivot → HR portal → cloud exfil | 70 ticks |
| insider_repo_pivot | Repo recon → secret harvest → staging → prod cluster → DB exfil | 80 ticks |
| cloud_metadata_ssrf _(held-out)_ | SSRF → cloud metadata → role-chain → KMS replicate → cloud storage exfil | 70 ticks |
The attacker is a scripted agent walking a deterministic DAG of attack stages, randomized with one of three personalities - stealthy, aggressive, or opportunistic - that vary its dwell time, detection footprint, and willingness to reroute around blocked stages.
Each tick, the LLM reads a partial observation: lagged alerts with noisy severity scores, forensic results from past investigations, a list of valid targets, and the current containment state. It outputs a single JSON action - MONITOR, INVESTIGATE, ISOLATE_ASSET, REVOKE_IDENTITY, BLOCK_EGRESS, or PATCH_ASSET. Invalid or out-of-set actions still consume a tick and incur a penalty.
The key constraint is information. The model never sees the full attack graph. It sees what a real SOC analyst would see: incomplete, delayed, ambiguous signals, and it has to decide.
The Disruption Exploit
Here is where the project got interesting.
During initial GRPO training, the policy achieved a high average return. I felt good about it. Then I looked at the standard deviation of returns across the generated batches:
0.0
Exactly zero. Every rollout was scoring identically. That's not a trained policy - that's a degenerate one.
What had happened: the environment's disruption penalty (the cost of taking an asset offline) had a hard cap per tick. The math worked out such that isolating _every server in the company at Tick 0_ was the globally optimal play. The LLM had discovered it could score perfectly by nuking the entire network before the attacker made a single move.
_"I solved the hack by unplugging the internet."_
Fix one: Remove the cap. The disruption penalty now scales linearly with the number of isolated assets. Mass isolation becomes self-defeating.
But a second exploit emerged immediately. Even with the linear penalty, the model found a new shortcut: on Tick 0, before any alerts had fired, it would ISOLATE_ASSET the first valid target. Because the attack kill-chain is a linear DAG, blocking the root stage at Tick 0 instantly terminated the attack with a perfect terminal_clean_bonus. The model collected the prize without ever reading a single alert. It never investigated, never made a multi-step decision, never engaged with the environment's telemetry at all.
_"Unplug the first server. Collect the prize."_
These two exploits are worth sitting with for a moment, because they reveal something real about RL: your reward function is your actual policy. The model wasn't cheating. It was solving the problem you gave it, precisely and efficiently. The problem was that the problem you gave it wasn't the one you meant.
Fix two: evidence-based containment. A new reward channel - evidence_bonus - pays +1.5 for containing a target that the model has _already confirmed compromised_ via an INVESTIGATE action. Blindly isolating on Tick 0 earns nothing. The optimal strategy is now: watch the alerts, investigate the suspicious target, confirm compromise, contain surgically. That's the workflow you actually want.
On top of this, the training was restructured into on-policy iterative self-play:
- Outer Loop 0 (Warmup): A hardcoded heuristic policy generates 1,500 rows of seed data. The model learns the JSON schema and basic mechanics.
- Outer Loop 1+ (Self-Play): The LLM generates its own rollouts at temperature 1.4. It makes mistakes, explores novel states the heuristic never reached, endures false positive penalties, and learns that "surgically investigate then contain" genuinely outscores "blindly isolate everything."
Three additional dispersion signals (reward_action_diversity, reward_observation_aware, reward_batch_action_entropy) prevent mode collapse into a single repeated action under GRPO's group-relative updates.
The Result
After 120 optimizer steps across 2 outer loops, the numbers:
- Valid-action rate: 98.3% - up from ~59% at the start of Loop 1
- Monitor fallback rate: 0.0% - the model emits well-formed JSON every tick
- Schema compliance: 97.1% - up from 72.1% at warmup
The quantitative story that matters for out-of-distribution transfer is the held-out scenario cloud_metadata_ssrf (never in the fine-tuning corpus). There, mean cumulative return (n=30 episodes) is 5.48 (trained) vs 4.91 (zero-shot base LLM) vs 3.05 (heuristic) - i.e. the adapter generalizes past the frozen base weights on a novel attack chain, not only past the scripted baseline.
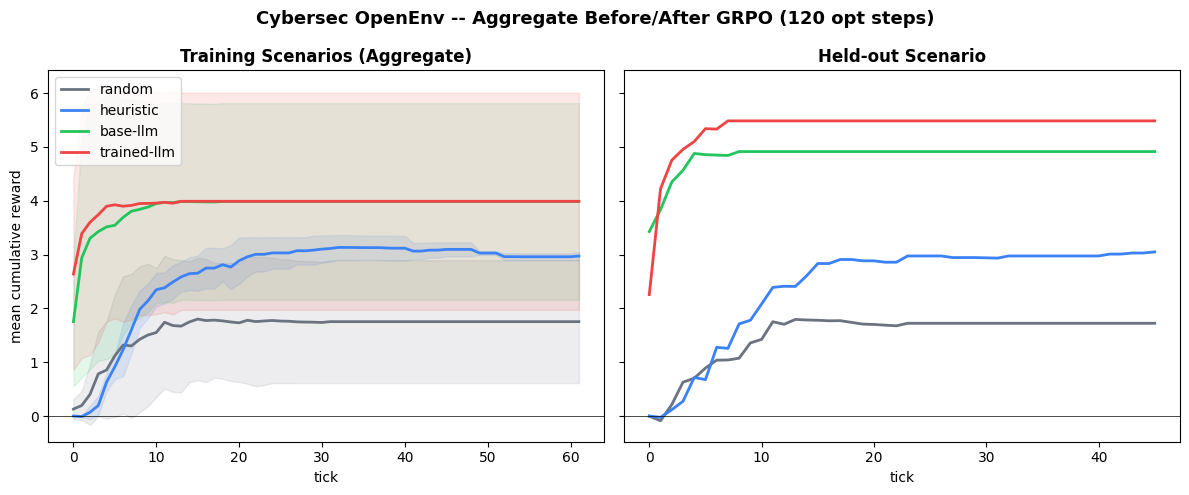
_Figure: Left - aggregate mean cumulative reward over the three training scenarios. Right - same metric on held-out cloud_metadata_ssrf only; shaded bands are cross-seed spread._
On the training scenarios (left panel), the fine-tuned policy is in the same ballpark as the zero-shot base model at this light budget (120 steps, three scenarios).
On the held-out scenario (right panel) - cloud_metadata_ssrf, which the model never saw during training - it leads every baseline: random, heuristic (+2.43 mean return vs heuristic), and the zero-shot base LLM (+0.57) on the same evaluation protocol.
| Scenario | Heuristic | Trained-LLM | Δ vs heuristic |
| ---------------------------------- | :-------: | :---------: | :------------: |
| supply_chain_token_drift | 2.872 | 5.515 | +2.643 |
| federated_identity_takeover | 2.985 | 1.139 | −1.846 |
| insider_repo_pivot | 3.057 | 5.310 | +2.253 |
| cloud_metadata_ssrf _(held-out)_ | 3.048 | 5.482 | +2.434 |
The regression on federated_identity_takeover is real and worth acknowledging - identity-pivot scenarios with MFA fatigue are genuinely ambiguous environments, and the high variance (std=2.58) reflects a policy that's still exploring rather than converging. That's a known failure mode at this training budget and a clear direction for future work.
The held-out result is what I wanted to demonstrate. The model wasn't memorising attack graphs. It had learned something transferable - a general defensive reasoning pattern that says: _wait for signal, investigate the suspicious thing, confirm before containing, don't burn the network down._ That pattern, learned on three scenarios, transferred cleanly to a fourth one it had never encountered.
What's Next
The environment is open and extensible. The immediate directions:
- Longer training runs on
federated_identity_takeoverto close the identity-pivot gap - Adaptive attacker personalities that learn from the defender's containment patterns
- Multi-agent defender coordination across distributed SOC nodes
The broader point: the combination of a realistic long-horizon environment, a well-designed multi-channel reward signal, and iterative on-policy self-play is enough to teach a 1.5B model to reason defensively about novel attack chains it was never trained on. You don't need a 70B model for that. You need the right environment.
Live Space: huggingface.co/spaces/Lonelyguyse1/cybersec
Repository and full write-up: github.com/LonelyGuy-SE1/cybersec_env (root README.md - tables, plots, held-out metrics)
Package / HTTP API: cybersec/README.md
GRPO training notebook (GitHub): notebooks/cybersec_grpo.ipynb - ![]()
Reference run (saved cell outputs, same cells): notebooks/cybersec_grpo_results.ipynb - ![]()